Preprocessed Strings for Asset IDs
Mick West posted up on his site a really good overview of some different methods for hashing string ids and gave good motivation for optimizing this area early on in a project. Please do review his article as it’s a prerequisite to this post, and his article is just really good.
I’ve been primarily concerned with memory management of strings as they are extremely hairy to work with. For me specifically I’ve ruled out the option of a string class — they hide important details and it’s too easy to write poor (but functional) code with them. This is just my opinion. Based on that opinion I’d like to achieve these points:
Avoid all dynamic memory allocation, or de-allocation Avoid complicated string data structures Little to no run-time string traversals (like strcmp) No annoying APIs that clutter the thought-space while writing/reading code Allow assets to refer to one another while on-disk or in-memory without complicated pointer translations There’s a lot I wanted to avoid here, and for good reason. If code makes use of dynamic memory, complicated data strctures, etc. that code is likely to suck in terms of both performance and maintenance. I’d like less features, less code, and some specific features to solve my specific problem: strings suck. The solution is to not use strings whenever possible, and when forced to use strings hide them under the rug. Following Jason Gregory’s example he outlined about Naughty Dog’s code base from his book “Game Engine Architecture 2nd Ed” I implemented the following solution, best shown via gif:
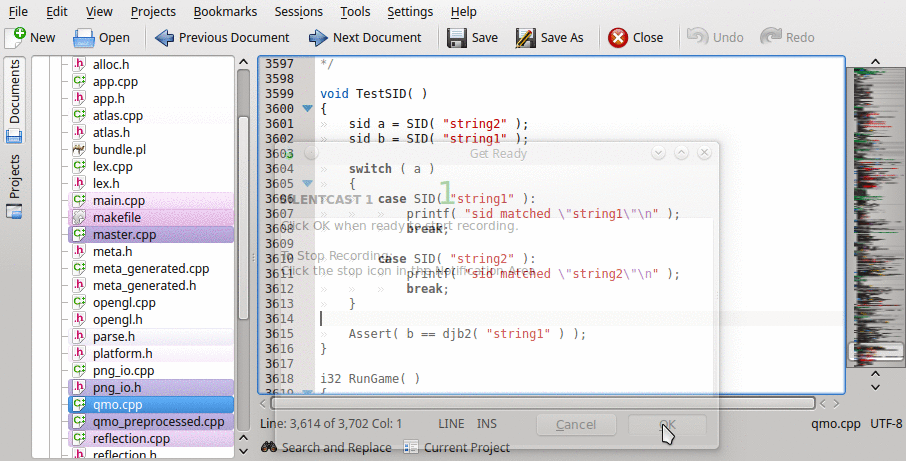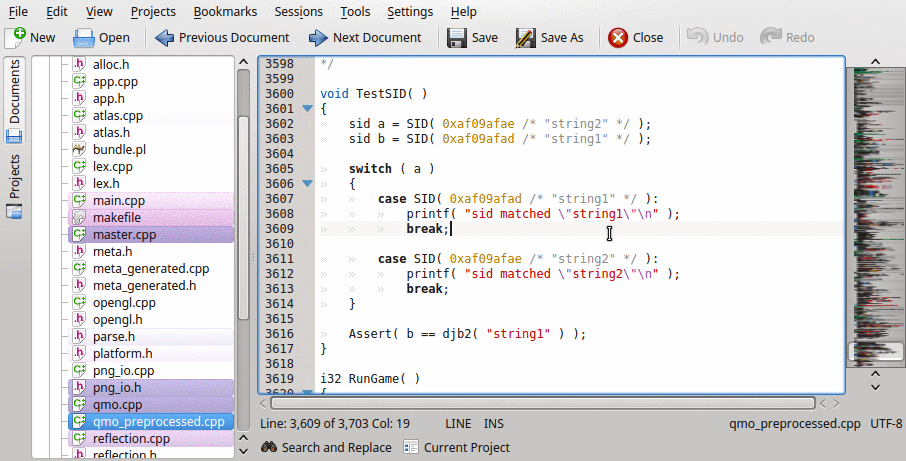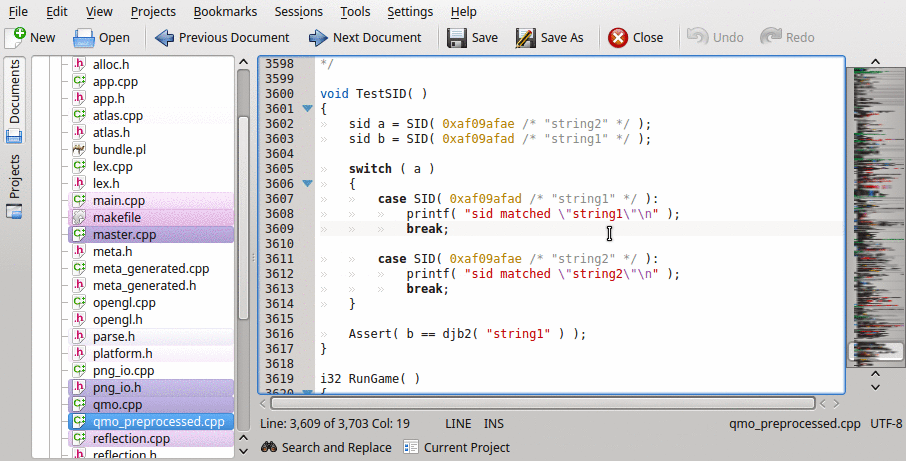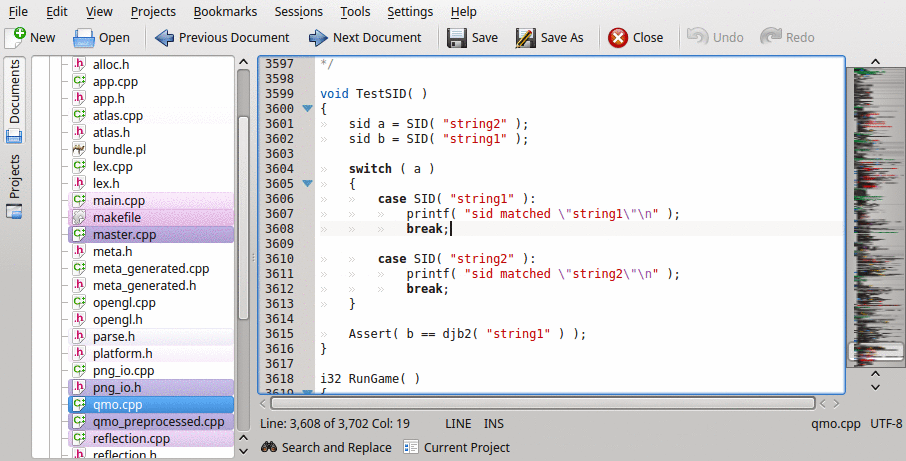
The SID (string id) is a macro that looks like (along with a typedef):
#define SID( string ) string
typedef sid int; // 32bit in my caseI’ve implemented a preprocessor in C that takes an input file, finds the SID macro instances, reads the string, hashes it and then inserts the hash along with the string stored as comment. Pretty much exactly what Mick talked about in his article.
Preprocessing files is fairly easy, though supporting this function might be pretty difficult, especially if there are a lot of source files that need to be pre-processed. Modifying build steps can be risky and sink a ton of time. This is another reason to hammer in this sort of optimization early on in a project in order to reap the benefits for a longer period of time, and not have to adjust heavy laid-in-stone systems after the fact.
Bundle Away the Woes
I’ve “stolen” Mitton’s bundle.pl program for use in my current project to recursively grab source files and create a single unified cpp file. This large cpp can then be fed to the compiler and compiled as a “unity build”. Since the bundle script looks for instances of the “#include” directive code can be written in almost the exact same manner as normal C++ development. Just make CPP files, include headers, and don’t worry about it.
The only real gotcha is if someone tries to do fancy inclusions by defining macros outside of files that affect the file inclusion. Since the bundle script is only looking for the #include directive (by the way it also comments out unnecessary code inclusions in the output bundled code) and isn’t running a full-blown C preprocessor, this can sometimes cause confusion.
It seems like a large relief on the linker and leaves me to thinking that C/C++ really ought to be used as single-translation unit languages, while leaving the linker mostly for hooking together separate libraries/code bases…
Compiling code can now look more or less like this:
perl bundle.pl bundle.cpp ./master.cpp
sid preprocessed.cpp bundle.cpp
g++ preprocessed.cpp -o out.exe
First collect all source into a single CPP, then preprocess the hash macros, and finally send the rest off to the compiler. Compile times should shrink, and I’ve even caught wind that modern compilers have an easier time with certain optimizations when fed only a single file (rumors! I can’t confirm this myself, at least not for a while).
Sweep it Under the Rug
Once some sort of string id is implemented in-game strings themselves don’t really need to be used all too often from a programmer’s perspective. However for visualization, tools, and editors strings are essential.
One good option I’ve adopted is to place strings for these purposes into global table in designated debug memory. This table can then be turned off or compiled away whenever the product is released. The idea I’ve adopted is to allow tools and debug visualization to use strings fairly liberally, albeit they are stored inside the debug table. The game code itself, along with the assets, refer to identifiers in hash-form. This allows product code to perform tiny translations from fully hashed values to asset indices, which is much faster and easier to manage compared to strings.
This can even be taken a step further; if all tools and debug visualizations are turned off and all that remains is a bunch of integer hash IDs, assets can then be “locked” for release. All hashed values can be translated directly into asset IDs such that no run-time translation is ever needed. For me specifically I haven’t quite thought how to implement such a system, and decided this level of optimization does not really give me a significant benefit.
Parting Thoughts
There are a couple of downsides to doing this style of compile-time preprocessing:
- Additional complexity in the build-step
- Layer of code opacity via SID macro
Some benefits:
- Huge optimization in terms of memory usage and CPU efficiency
- Can run switch statement on SID strings
- Uniquely identify assets in-code and on-disk without costly or complicated translation
If the costs can be mitigated through implementing some kind of code pre-processor/bundler early on then it’s possible to be left with just a bunch of benefits :)
Finally, I thought it was super cool how hashes like djb2 and FNV-1a use an initializer value to start the hashing, typically a carefully chosen prime. This allows to hash a prefix string, and then feed the result off to hash the suffix. Mick explains this in his article this idea of combining hashed values as a useful feature for supporting tools and assets. This can be implemented both at compile or run-time (though I haven’t quite thought of a need to do this at compile-time yet):
int h0 = hash( "str" );
int h1 = hash( h0, "ing" );
int h2 = hash( "string" );
assert( h1 == h2 );